FAIR Universe HEP Challenge
hep_challenge.datasets module
- class hep_challenge.datasets.Data(input_dir, test_size=0.3)
Bases:
objectA class to represent a dataset.
- Parameters:
input_dir (str): The directory path of the input data.
- Attributes:
__train_set (dict): A dictionary containing the train dataset.
__test_set (dict): A dictionary containing the test dataset.
input_dir (str): The directory path of the input data.
- Methods:
load_train_set(): Loads the train dataset.
load_test_set(): Loads the test dataset.
get_train_set(): Returns the train dataset.
get_test_set(): Returns the test dataset.
delete_train_set(): Deletes the train dataset.
get_syst_train_set(): Returns the train dataset with systematic variations.
- delete_train_set()
Deletes the train dataset.
- get_test_set()
Returns the test dataset.
- Returns:
dict: The test dataset.
- get_train_set()
Returns the train dataset.
- Returns:
dict: The train dataset.
- hep_challenge.datasets.download_public_dataset()
Downloads and extracts the Neurips 2024 public dataset.
- Returns:
Data: The path to the extracted input data.
- Raises:
HTTPError: If there is an error while downloading the dataset. FileNotFoundError: If the downloaded dataset file is not found. zipfile.BadZipFile: If the downloaded file is not a valid zip file.
hep_challenge.ingestion module
- class hep_challenge.ingestion.Ingestion(data=None)
Bases:
objectClass for handling the ingestion process.
- Args:
data (object): The data object.
- Attributes:
start_time (datetime): The start time of the ingestion process.
end_time (datetime): The end time of the ingestion process.
model (object): The model object.
data (object): The data object.
- compute_result()
Compute the ingestion result.
- fit_submission()
Fit the submitted model.
- get_duration()
Get the duration of the ingestion process.
- Returns:
timedelta: The duration of the ingestion process.
- init_submission(Model)
Initialize the submitted model.
- Args:
Model (object): The model class.
- load_train_set(**kwargs)
Load the training set.
- Returns:
object: The loaded training set.
- predict_submission(test_settings, initial_seed=31415)
Make predictions using the submitted model.
- Args:
test_settings (dict): The test settings.
- save_duration(output_dir=None)
Save the duration of the ingestion process to a file.
- Args:
output_dir (str): The output directory to save the duration file.
- save_result(output_dir=None)
Save the ingestion result to files.
- Args:
output_dir (str): The output directory to save the result files.
- start_timer()
Start the timer for the ingestion process.
- stop_timer()
Stop the timer for the ingestion process.
hep_challenge.score module
- class hep_challenge.score.Scoring(name='')
Bases:
objectThis class is used to compute the scores for the competition. For more details, see the evaluation page.
- Atributes:
start_time (datetime): The start time of the scoring process.
end_time (datetime): The end time of the scoring process.
ingestion_results (list): The ingestion results.
ingestion_duration (float): The ingestion duration.
scores_dict (dict): The scores dictionary.
- Methods:
start_timer(): Start the timer.
stop_timer(): Stop the timer.
get_duration(): Get the duration of the scoring process.
show_duration(): Show the duration of the scoring process.
load_ingestion_duration(ingestion_duration_file): Load the ingestion duration.
load_ingestion_results(prediction_dir=”./”,score_dir=”./”): Load the ingestion results.
compute_scores(test_settings): Compute the scores.
RMSE_score(mu, mu_hat, delta_mu_hat): Compute the RMSE score.
MAE_score(mu, mu_hat, delta_mu_hat): Compute the MAE score.
Quantiles_Score(mu, p16, p84, eps=1e-3): Compute the Quantiles Score.
write_scores(): Write the scores.
write_html(content): Write the HTML content.
_print(content): Print the content.
save_figure(mu, p16s, p84s, set=0): Save the figure.
- MAE_score(mu, mu_hat, delta_mu_hat)
Compute the mean absolute error between the true value mu and the predicted value mu_hat.
- Args:
mu (float): The true value.
mu_hat (np.array): The predicted value.
delta_mu_hat (np.array): The uncertainty on the predicted value
- Quantiles_Score(mu, p16, p84, eps=0.001)
Compute the quantiles score based on the true value mu and the quantiles p16 and p84.
- Args:
mu (array): The true ${mu} value.
p16 (array): The 16th percentile.
p84 (array): The 84th percentile.
eps (float, optional): A small value to avoid division by zero. Defaults to 1e-3.
- RMSE_score(mu, mu_hat, delta_mu_hat)
Compute the root mean squared error between the true value mu and the predicted value mu_hat.
- Args:
mu (float): The true value.
mu_hat (np.array): The predicted value.
delta_mu_hat (np.array): The uncertainty on the predicted value.
- compute_scores(test_settings, no_html=False)
Compute the scores for the competition based on the test settings.
- Args:
test_settings (dict): The test settings.
- load_ingestion_duration(ingestion_duration_file)
Load the ingestion duration.
- Args:
ingestion_duration_file (str): The ingestion duration file.
- load_ingestion_results(prediction_dir='./', score_dir='./')
Load the ingestion results.
- Args:
prediction_dir (str, optional): location of the predictions. Defaults to “./”. score_dir (str, optional): location of the scores. Defaults to “./”.
- save_figure(mu, p16s, p84s, true_mu=None, set=0)
Save the figure of the mu distribution.
- Args:
mu (array): The true ${mu} value.
p16 (array): The 16th percentile.
p84 (array): The 84th percentile.
set (int, optional): The set number. Defaults to 0.
hep_challenge.visualization module
- class hep_challenge.visualization.Dataset_visualise(data_set, name='dataset', columns=None)
Bases:
objectA class for visualizing datasets.
- Parameters:
data_set (dict): The dataset containing the data, labels, weights, and detailed labels.
name (str): The name of the dataset (default: “dataset”).
columns (list): The list of column names to consider (default: None, which includes all columns).
- Attributes:
dfall (DataFrame): The dataset.
target (Series): The labels.
weights (Series): The weights.
detailed_label (ndarray): The detailed labels.
columns (list): The list of column names.
name (str): The name of the dataset.
keys (ndarray): The unique detailed labels.
weight_keys (dict): The weights for each detailed label.
- Methods:
examine_dataset(): Prints information about the dataset.
histogram_dataset(columns=None): Plots histograms of the dataset features.
correlation_plots(columns=None): Plots correlation matrices of the dataset features.
pair_plots(sample_size=10, columns=None): Plots pair plots of the dataset features.
stacked_histogram(field_name, mu_hat=1.0, bins=30): Plots a stacked histogram of a specific field in the dataset.
pair_plots_syst(df_syst, sample_size=10): Plots pair plots between the dataset and a system dataset.
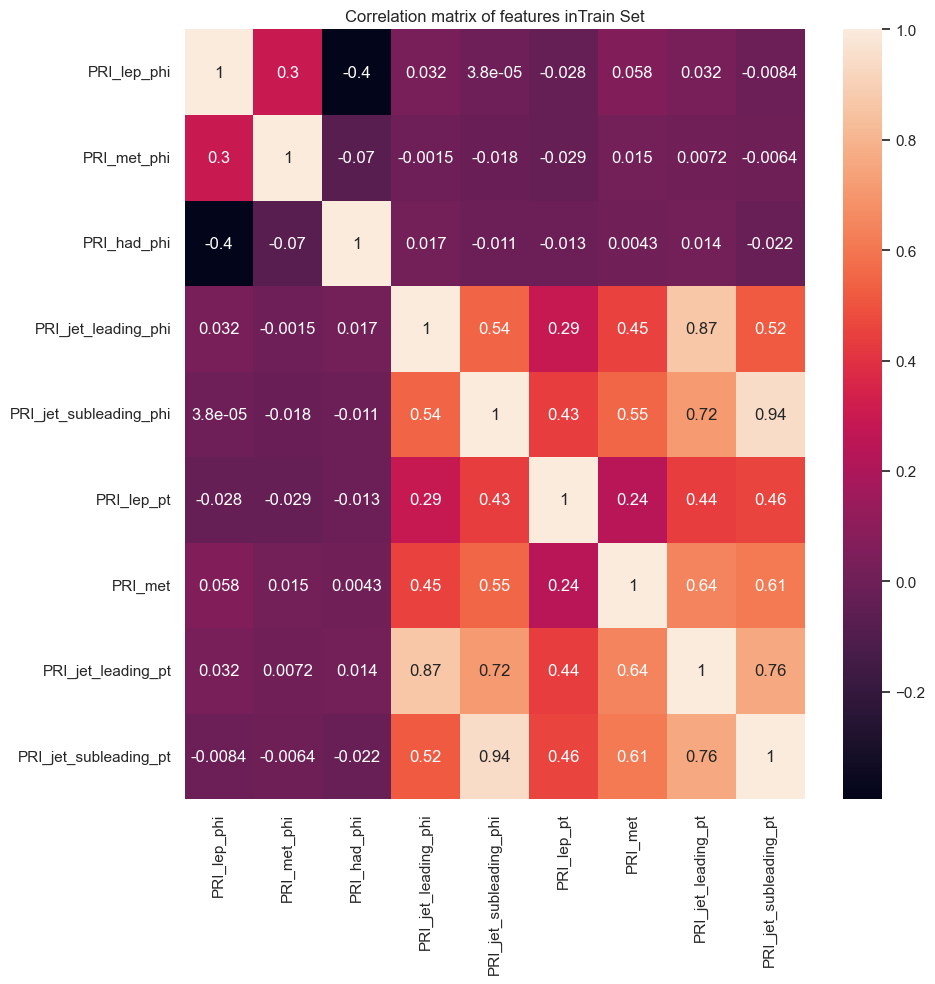
- correlation_plots(columns=None)
Plots correlation matrices of the dataset features.
Args: * columns (list): The list of column names to consider (default: None, which includes all columns).
- examine_dataset()
Prints information about the dataset.
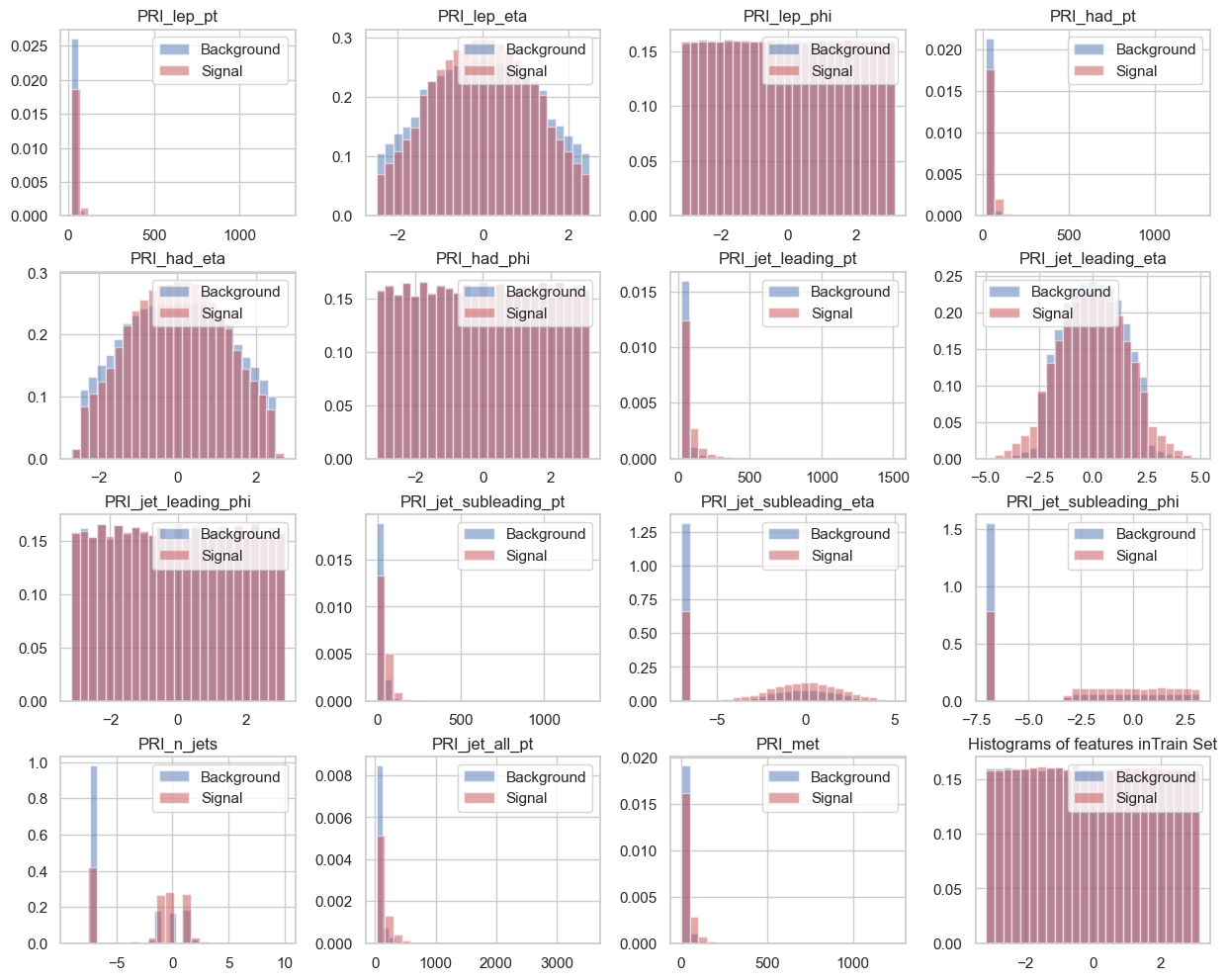
- histogram_dataset(columns=None, nbin=25)
Plots histograms of the dataset features.
- Args:
columns (list): The list of column names to consider (default: None, which includes all columns).
nbin (int): The number of bins for the histogram (default: 25).
- pair_plots(sample_size=10, columns=None)
Plots pair plots of the dataset features.
- Args:
sample_size (int): The number of samples to consider (default: 10).
columns (list): The list of column names to consider (default: None, which includes all columns).

- pair_plots_syst(df_syst, sample_size=100)
Plots pair plots between the dataset and a system dataset.
- Args:
df_syst (DataFrame): The system dataset.
sample_size (int): The number of samples to consider (default: 10).
..images:: images/pair_plot_syst.png
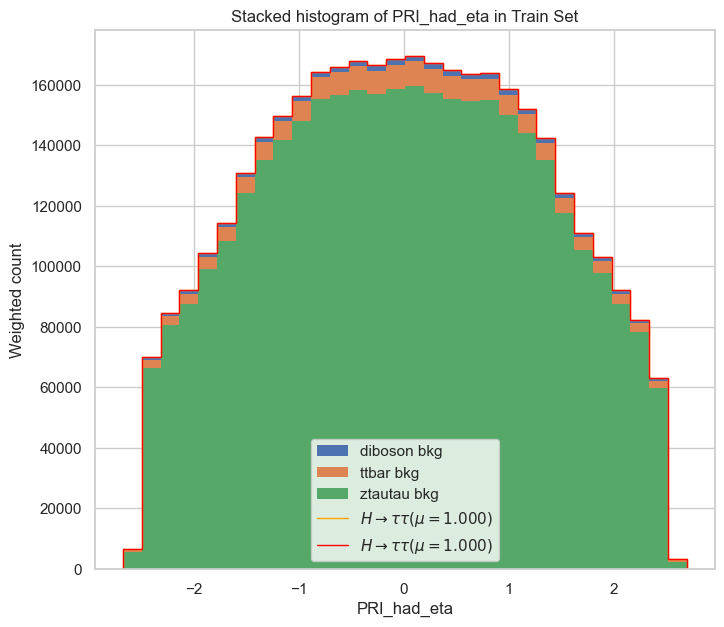
- stacked_histogram(field_name, mu_hat=1.0, bins=30, y_scale='linear')
Plots a stacked histogram of a specific field in the dataset.
- Args:
field_name (str): The name of the field to plot.
mu_hat (float): The value of mu (default: 1.0).
bins (int): The number of bins for the histogram (default: 30).
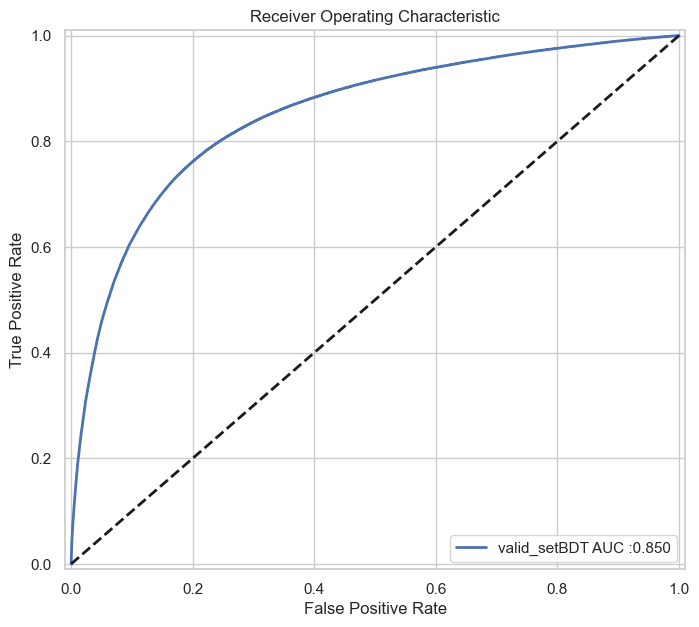
- hep_challenge.visualization.roc_curve_wrapper(score, labels, weights, plot_label='model', color='b', lw=2)
Plots the ROC curve.
- Args:
score (ndarray): The score.
labels (ndarray): The labels.
weights (ndarray): The weights.
plot_label (str, optional): The plot label. Defaults to “model”.
color (str, optional): The color. Defaults to “b”.
lw (int, optional): The line width. Defaults to 2.
- hep_challenge.visualization.visualize_coverage(ingestion_result_dict, ground_truth_mus)
Plots a coverage plot of the mu values.
- Args:
ingestion_result_dict (dict): A dictionary containing the ingestion results.
ground_truth_mus (dict): A dictionary of ground truth mu values.

- hep_challenge.visualization.visualize_scatter(ingestion_result_dict, ground_truth_mus)
Plots a scatter Plot of ground truth vs. predicted mu values.
- Args:
ingestion_result_dict (dict): A dictionary containing the ingestion results.
ground_truth_mus (dict): A dictionary of ground truth mu values.
